Automated archiving process for older ( or infrequently accessed ) files (or objects) which are stored in AWS EC2 (in EBS/EFS) environments”
1 Problem
This was done as part of a cost saving project. The project was to save the cost that we spend on the cloud infrastructure. During the evaluation it was identified that there are a lot of old files stored in EBS storage, and those files are not being accessed frequently/regularly. Furthermore, new files are being added to these storage day by day. So the problem was
“Do we really need to keep these files stored in EBS or is there any other option where we can move these to somewhere else and save the cost ?”
2 Solution
The agreed solution was to move old data to S3 object storage. As new files are being added to the storage day by day, it was required to automate the process.
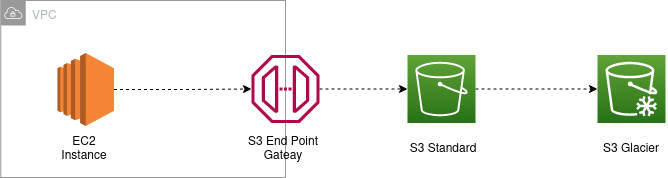
2.1 Implementation Guide
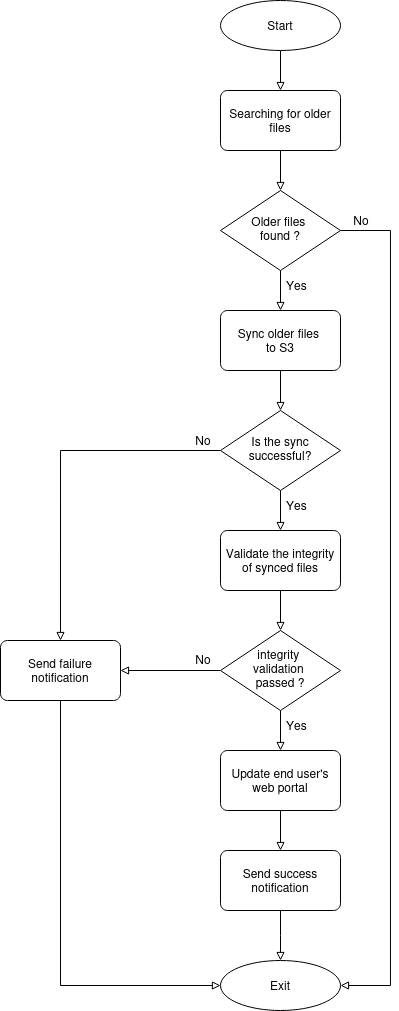
Flow chart of the implemented-logic is described below,
AWS CLI was used to copy data from EC2 (EBS/EFS storage) instances to S3. The AWS EC2 instance was assigned a role with required permission to write to S3, so it is easier to automate the process. We used the AWS sync command to copy (this is a data sync) data from EC2 to S3.
aws s3 sync <local_path> s3://<bucket_name>The assigned user role required necessary permissions to write to the specific bucket. Following IAM policy was used to grant access to the S3. Further to improve the security of the automated process, it is only allowed to read and write to S3 (No delete operations can be performed).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::<bucket_name>"
]
},
]
}Once data is moved from EBS to S3 object storage, lifecycle policies are used to move data to glacier storage. This helps us to further save the cost.
2.1.1 Integrity check
To make sure the files are being moved from EC2 to S3 without any alterations in the middle, we included an integrity checking step to the archival process. We used md5sum to generate the integrity of local files.
md5sum /path/to/file | awk '{print $1}'To find the checksum of the files copied to S3 (files in S3), you can use the ETag property. This can be found from the object’s metadata. Following command can be used to get the metadata of a list of objects in S3 bucket.
aws s3api list-objects --bucket <bucket_name>
#Response will looks like this,
{
"Key": "file_path",
"LastModified": "modified_date",
"ETag": "hash",
"Size": size_of_the_file,
"StorageClass": "storage_class",
"Owner": {
"DisplayName": "owner_name",
"ID":"owner_id"
}
},2.1.2 Monitoring and Alerting
It is essential to get notified about the process status. So we have introduced an alerting step to our automated process. So the technical teams are getting notified on both successful runs and failures.
2.1.3 Retrieval process,
Users were given a web portal to see the list of archived objects. And users can retrieve the archived objects ((Copy from S3 to user’s FTP home directory)) via the given web portal.